Into the ever rising ocean of data

Data is, at the same time, the most mundane and most exciting aspect of computing.
It is mundane because of its origins in the world of folders and filing cabinets. In my first ever paid programming job, for a government department in the 1980s, the team I was part of was not called Information Technology (and certainly not Digital), but Automated Data Processing. And, while I was thrilled to get paid for writing code, the work we were doing was about as exciting as that title implies: we were doing the computing equivalent of shoveling coal from one pile to another (or moving records from one file to another). All of the data we were working already existed, in written paper records, in printed documents or even on micro-fiche. By creating Automated Data Processing systems, we were enabling data to be processed with greater speed and accuracy - but we were not creating new data.
Based on some informal surveys, I think that most people who have not had the chance to work in technical jobs, still think of data in this way. When we press ‘send’ on our mobile banking app, we imagine that the work that computers are doing is similar to the work that clerks would have done with printed ledgers many years ago: the data is hauled up from the memory of the computer, the number is read and sent out, some amendments may be made, and the data is sent back to its quiet resting place.
In some ways, that image is still accurate. The core transaction that you trigger when you press ‘send’ still results in the retrieval, reading and possible update of a small number of records that are a reliable source of truth - just like a clerk updating a ledger.
But, things have changed a lot since the 1980s. Back then, it was expensive and slow to store and retrieve data. We had only just got started on the business of computerising processes which had been manual for decades or even centuries. Getting a few records updated accurately was enough of an achievement for us.
It’s very different now. While data storage and computing power are still major costs for every enterprise, compared to the 1980s, they are effectively free and instantaneous. This means that computers can do a lot more than simply look up your bank balance and update it. Imagine that clerk with the ledger again. Now imagine that, on the way to pick up the ledger, the clerk was able to check every transaction you had ever made, to compare your pattern of activity with the activity of other people in your circumstances, to figure out the likelihood that you were a fraudster, or that you might be about to ask for a loan, or that you might be struggling to repay the debt that you already have. To achieve all of this analysis and all those tasks the clerk would have to have superpowers - we can imagine them moving in a blur. This is why the computerised transaction is not just a more efficient version of the manual transaction - it is something new and different.
Now let’s extend our imagination a little further. Imagine that the impossibly fast moving clerk is not just looking up information about you and other customers like you. Imagine that they are also writing things down - about the time of day, the transaction you are performing, how busy the branch was, possibly even the expression on your face or the tone of your voice. The ability we have to process data today is so great, and the value of that data is so high, that very few opportunities to capture data will be ignored. When you hit ‘send’ on your mobile banking app, you are not merely requesting data, you are creating data: your interest in conducting this transaction at this time from this device in this place are all facts to be recorded.
If you work with technologists, you may have heard them talk about data marts, data warehouses and data lakes. If we reflect on the new data which is being created every data, and the new ways of creating data which are being created every data, we soon realise that we are all part of an ocean of data - and the ocean is rising fast.
There are lots of difficult questions we should ask ourselves about how we should live in a world in which so much data is recorded and processed. I’m not going to attempt to tackle those here - they deserve much longer and deeper consideration. Instead, I will simply observe that such a world is now reality and becoming more real every day. Just as the systems I worked in the 1980s seem primitive today, and only caught a mere sliver of the data required to describe the world, the systems of today will seem primitive in just a few years. Throughout this series of articles, I have argued that those of us who work with technology have a duty to explain the world we are building: I think that this duty is particularly strong in the field of data.
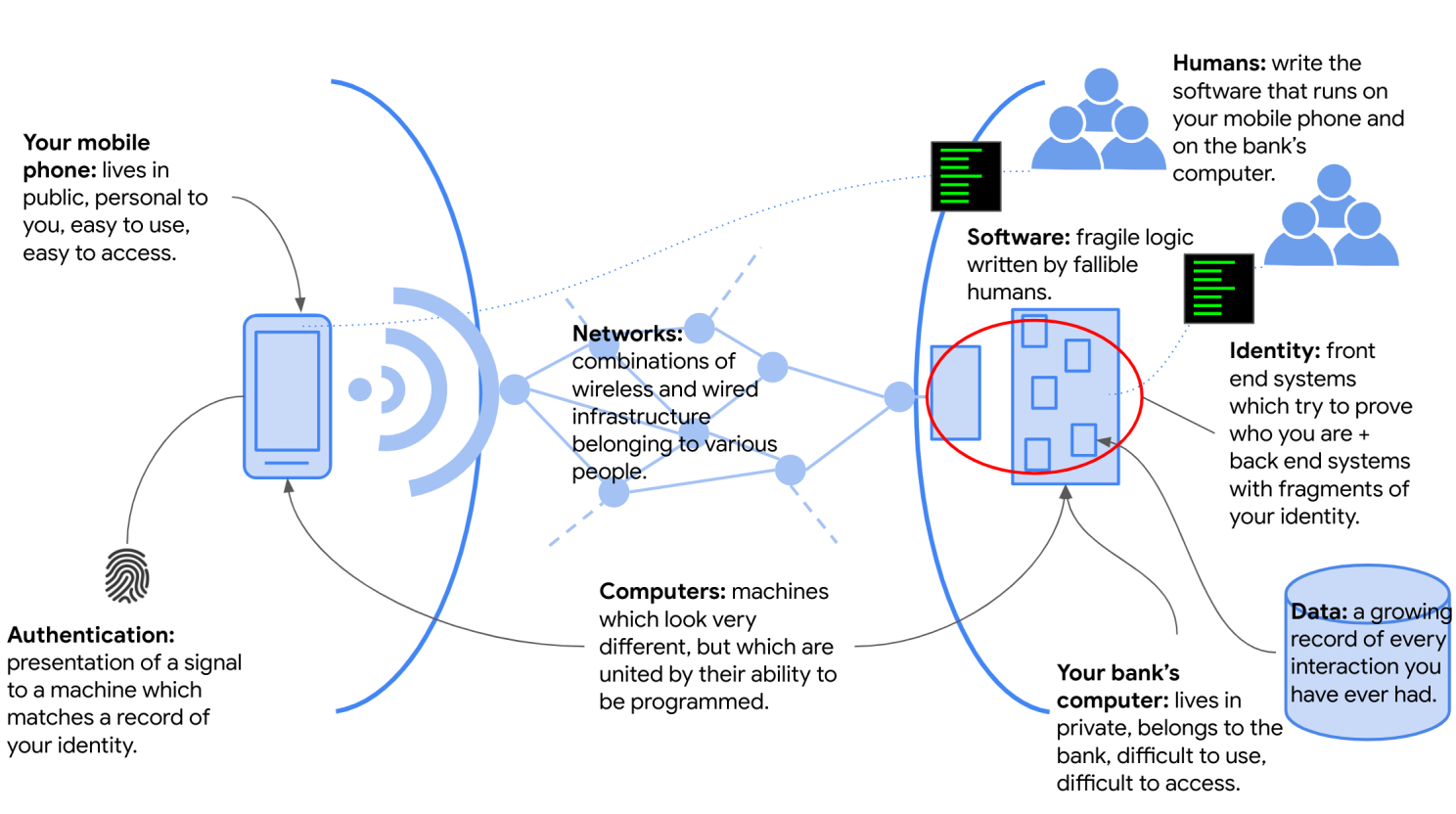
The Round Trip Question: Journey Map
This series of articles is driven by a conviction that computing is increasingly important to our lives, but many people don’t understand how computing works, and that those of us working in the industry therefore have a duty to explain. It attempts to answer The Round Trip Question: what happens when you press ‘send’ on the mobile banking app on your phone?
I’m using this section at the bottom to capture the list of questions which arise as I write each article. If I go wrong, or if you have other questions, please tell me in the comments.
To-do:
Who are all these humans who write code? How do they work?
Why do action heroes ‘break into the computer room to hack the mainframe’? How realistic is that? What’s a mainframe? What’s a computer room?
There are a couple more questions to go. For now, though, here’s the very rough picture of what we have covered so far: