Planning for a cloudy day

On 3rd June 1979, the American Institute of Architects held their annual national conference at the Kemper Arena in Kansas City, a building they had honoured with an award.
Less than 24 hours later, the roof collapsed. Fortunately, no-one was hurt.
The cause of the collapse was partly due to excessive rainfall during a major storm. The roof has been built with rain in mind, with a drainage system designed to release water gradually into the sewer system to avoid overwhelming it. What it had not been designed for, however, was the day when there was so much rain that the sewer system was already overwhelmed, causing water to back up onto the roof. Water is heavy, and the additional weight, coupled with high winds, caused a supporting bolt to give way, triggering a series of further failures and the collapse of the roof.
There’s an important design lesson here: we need to anticipate and design for multiple different causes of failure (avoiding overwhelming the sewer system; and coping with a sewer system which is already overwhelmed). And the solution for each potential cause of failure is unlikely to be the same (a system to gradually release rainwater doesn’t help when the water has nowhere to go).
This lesson is as important for enterprise adoption of public Cloud as it is for the design of physical buildings.
One of the questions which technology architects often get asked when they are planning a move to public Cloud is: “What if <insert name of Cloud provider here> goes wrong?”
The best answer to this question is another question: “What do you mean by ‘goes wrong?’” This is not an attempt to be difficult; it is an attempt to be precise. It is important to know what type of failure we are attempting to design for. (Are we controlling the release of rainwater, or are we dealing with an overwhelmed sewer system?)
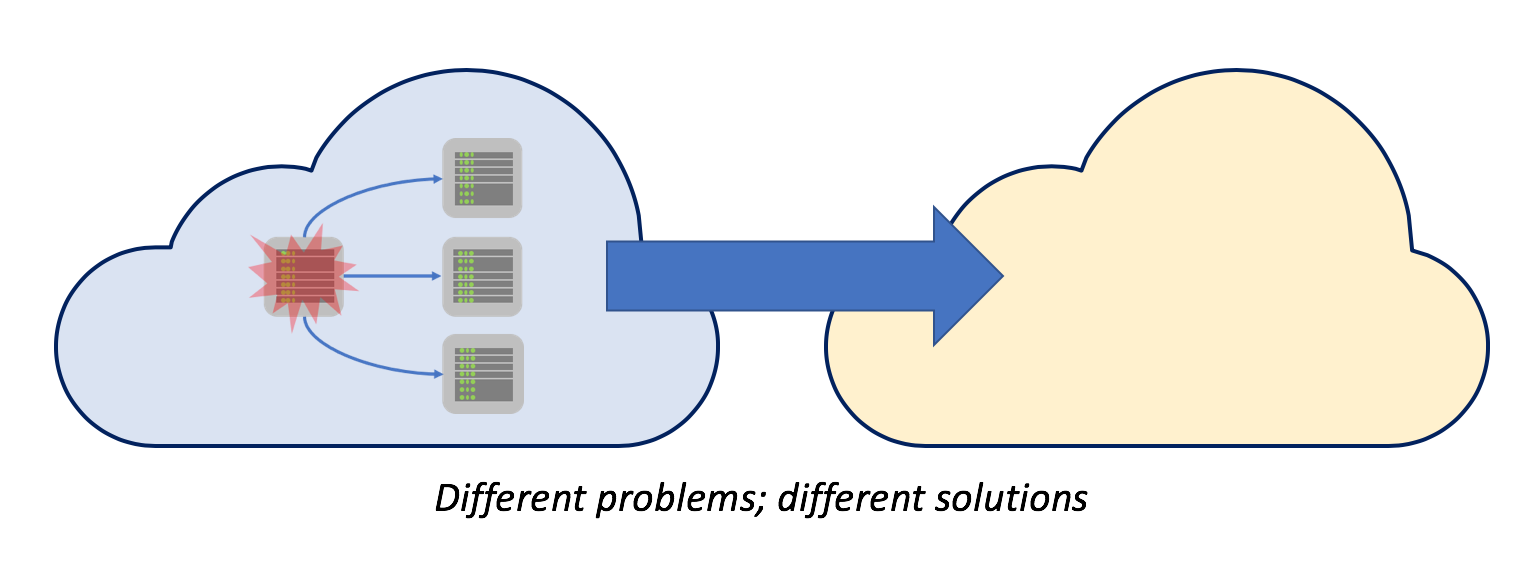
One type of failure which people may have in mind is the technical failure of all or part of a service.
In this case, I believe that the best approach is to use the resilience characteristics available within each Cloud provider’s services: to fail between nodes in a zone, to fail between zones, or even to fail between regions. I also believe that we can make the most of these resilience characteristics by being Cloud ambidextrous rather than Cloud agnostic: that is, by using the native managed services within each Cloud provider, and by using features such as automatic, redundant data distribution across geographies. If we use these services well, then many of the technical failures which require manual intervention in on-premise data centres are dealt with seamlessly and automatically.
There are alternative approaches. We could attempt to deal with technical failure by running the same service across multiple Cloud providers. However, I think that this would be a mistake. It would force us to be Cloud agnostic, and to deny ourselves the resilience characteristics built into native Cloud services. It would also force us to solve the complicated problem of distributing data and services across multiple Cloud providers to achieve, for our most important services, recovery without data loss or interruption to service. I believe that such a design would be complex, fragile and more prone to failure, for the sake of addressing a highly unlikely scenario: the complete failure of a Cloud provider’s infrastructure and all associated resilience features. Given the scale of services operated by Cloud providers, this scenario is much less probably than the (still very improbable) risk of multiple data centre failures which most enterprises are already exposed to.
However, this is not the only type of failure we should worry about. Whatever the resilience characteristics of a Cloud provider’s services, Cloud providers are suppliers, we have commercial relationships with them, and commercial relationships can go wrong. Companies can fall out with each other and companies can fail. This is certainly not the intent when we sign the contract, but if we are wise, we plan for this eventuality.
I believe that the best approach to this type of failure, especially for large enterprises, is to maintain relationships with more than one Cloud provider. Again, the goal is not to create a situation where we can switch services instantly between providers in the event of a technical failure: it is to give us an alternative in the event of a commercial failure. And, as commercial failures are not as swift as technical failures, if we remain Cloud ambidextrous then we have the ability to make the most of Cloud native services, while having the ability to migrate services within a reasonable time if the relationship goes sour.
So, the answer to the question ‘What if X goes wrong?’ continues to be “Goes wrong in what way?” If we are not clear about which type of failure we are talking about for enterprise Cloud then we will get confused: we may plan adequately for technical failure, but have nowhere to go in the event of a commercial breakdown; or we may develop complex technical approaches to solving commercial problems which make us less able to respond to technical failure.
Planning for failure requires a combination of imagination and precision. The real world will continue to take us by surprise: the best we can do is to anticipate the different ways in which our solutions will fail, and the different ways we need to respond to those failures.